
Vera 的综合性能评估:跨医学知识领域的多基准测试评估
摘要
我们对 Vera 进行了综合评估,这是一款先进的临床决策支持系统,旨在为医疗服务提供者提供即时、循证的医学指导。Vera 利用先进的 AI 智能体和检索增强生成(RAG)技术,综合分析超过 6000 万篇经同行评审的医学文献中的知识,提供可靠且符合语境的答案。本次多基准测试评估考察了 Vera 在三个不同医学知识领域的性能:美国医师执照考试(USMLE)、《新英格兰医学杂志》AI 问答数据集(NEJM-AI)以及 MedXpertQA 基准测试。在 USMLE 上,Vera 取得了 97.5 % 的优异整体准确率,各阶段准确率分别为 97.9 %(Step 1)、98.2 %(Step 2 CK)和 96.7 %(Step 3)。在涵盖五个医学专科共 655 道题目的 NEJM-AI 基准测试中,Vera 以 84.9 % 的准确率展现出卓越性能,超越了包括 OpenAI o4 Mini(77.1 %)、Claude 4 Sonnet(75.4 %)和 Perplexity Sonar Pro(74.4 %)在内的领先 AI 模型。在涵盖多个身体系统和医学任务共 500 道题目的 MedXpertQA 基准测试中,Vera 取得了 62.2 % 的准确率,在专科临床推理场景中表现出色。Vera 在 NEJM-AI 五个医学专科中的四个取得了最高准确率,在儿科(93.9 %)和内科(87.3 %)方面表现尤为突出。这些跨多样评估框架的结果凸显了 Vera 强大的医学知识表征和推理能力,使其成为临床决策支持的领先解决方案。
引言
各类临床环境中的医疗服务提供者需要快速获取准确、循证的医学知识,以支持最佳的患者诊疗。医学文献的指数级增长为及时的知识检索与综合带来了前所未有的挑战。Vera 通过将先进的 AI 智能体与先进的检索增强生成技术相结合来应对这一关键需求,其提供可靠临床指导的速度约为传统方法的十倍。
对医学 AI 系统的评估需要跨多个领域进行严格评估,以确保其在真实临床场景中具有稳健的性能。尽管单一基准测试能够提供有价值的见解,但跨多样知识框架的综合评估能够更全面地呈现系统的能力和局限性。本研究采用三个互补的评估框架对 Vera 进行了多基准测试评估:美国医师执照考试(USMLE)、《新英格兰医学杂志》AI 问答数据集(NEJM-AI)以及 MedXpertQA 基准测试。
USMLE 提供了一种标准化的衡量方式,用以评估涵盖基础科学、临床知识和患者管理领域的基础医学知识。然而,它主要反映执照取得前的教育内容,可能无法充分体现当代临床决策的复杂性。为弥补这一局限,我们采用 NEJM-AI 基准测试作为补充评估,该基准测试包含跨五大医学专科的 655 道临床导向题目,能够洞察在更贴近实践场景中的性能表现。此外,我们还在 MedXpertQA 基准测试上对 Vera 进行了评估,该基准包含 500 道题目,考察跨多样身体系统、医学任务和题型的临床推理能力,进一步揭示了专科临床知识领域的表现。
我们在这些不同评估框架上的综合分析揭示了 Vera 的优势和性能特征,表明其在变革临床决策支持、提升医疗服务提供者效率并最终改善患者诊疗质量方面具有巨大潜力。
结果
多基准测试性能概览
Vera 在全部三个评估框架中均表现卓越,在 USMLE 上取得 97.5%,在 NEJM-AI 基准测试上取得 84.9%,在 MedXpertQA 基准测试上取得 62.2%。表 1 总结了 Vera 在所有评估中的性能表现。
| 基准测试 | 准确率 |
|---|---|
| USMLE(整体) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI(整体) | 84.9 % |
| MedXpertQA(整体) | 62.2 % |
USMLE 性能分析
在 USMLE 评估中,Vera 在所有考试层级均取得近乎完美的准确率,展现出稳健的基础医学知识。各阶段之间的微小差异(范围:96.7–98.2 %)表明,Vera 的知识表征能够从基础科学概念有效扩展到需要患者管理决策的复杂临床场景。
USMLE 竞争分析
Vera 的性能在标准化医学知识评估中确立了相对于其他医学 AI 系统的明显优势。图 1 展示了 Vera 在医学 AI 领域的竞争优势。
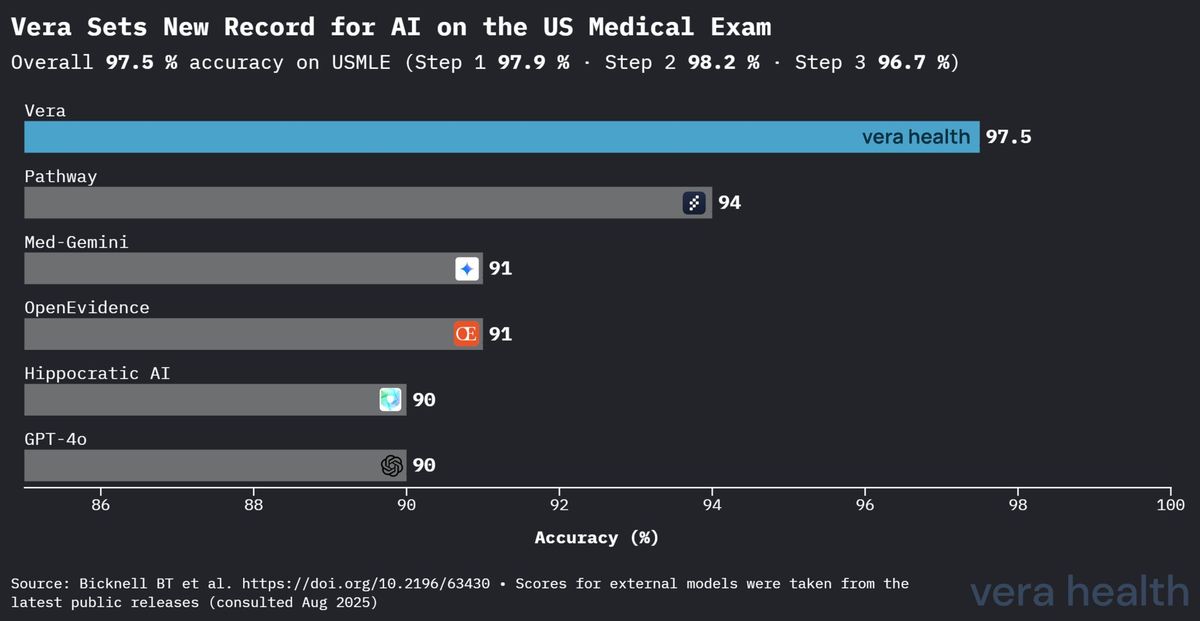
这一竞争分析揭示了几项关键见解:(1)Vera 相对于第二佳模型 3.5 个百分点的领先优势代表了医学知识评估方面的实质性提升;(2)与通用模型相比,性能差距显著扩大,凸显了医学专用优化的价值;(3)Vera 的优势同时覆盖专科医学 AI 系统和领先的通用语言模型。
NEJM-AI 竞争基准测试结果
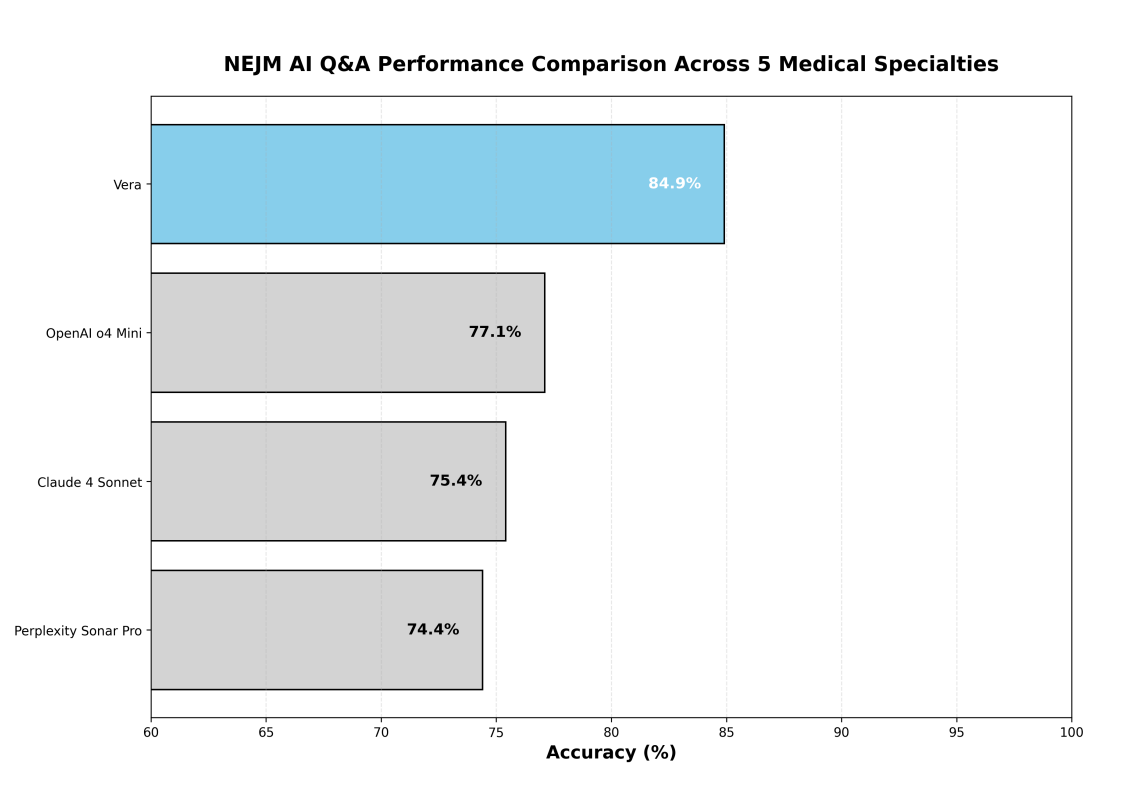
在 NEJM-AI 基准测试中,Vera 在所有受评模型中取得了最高的整体准确率,以显著优势超越领先的 AI 系统。图 2 展示了 Vera 的竞争优势。
专科特定性能分析
Vera 的性能在各医学专科之间有所不同,但在大多数领域均表现稳定且出色。表 2 列出了详细的专科特定准确率。
| 医学专科 | 题目数 | Vera 准确率 |
|---|---|---|
| 儿科 | 99 | 93.9 % |
| 精神科 | 150 | 88.7 % |
| 内科 | 126 | 87.3 % |
| 普通外科 | 141 | 83.0 % |
| 妇产科 | 139 | 74.1 % |
图 3 详细比较了 Vera 与竞争模型在全部五个医学专科上的性能表现。
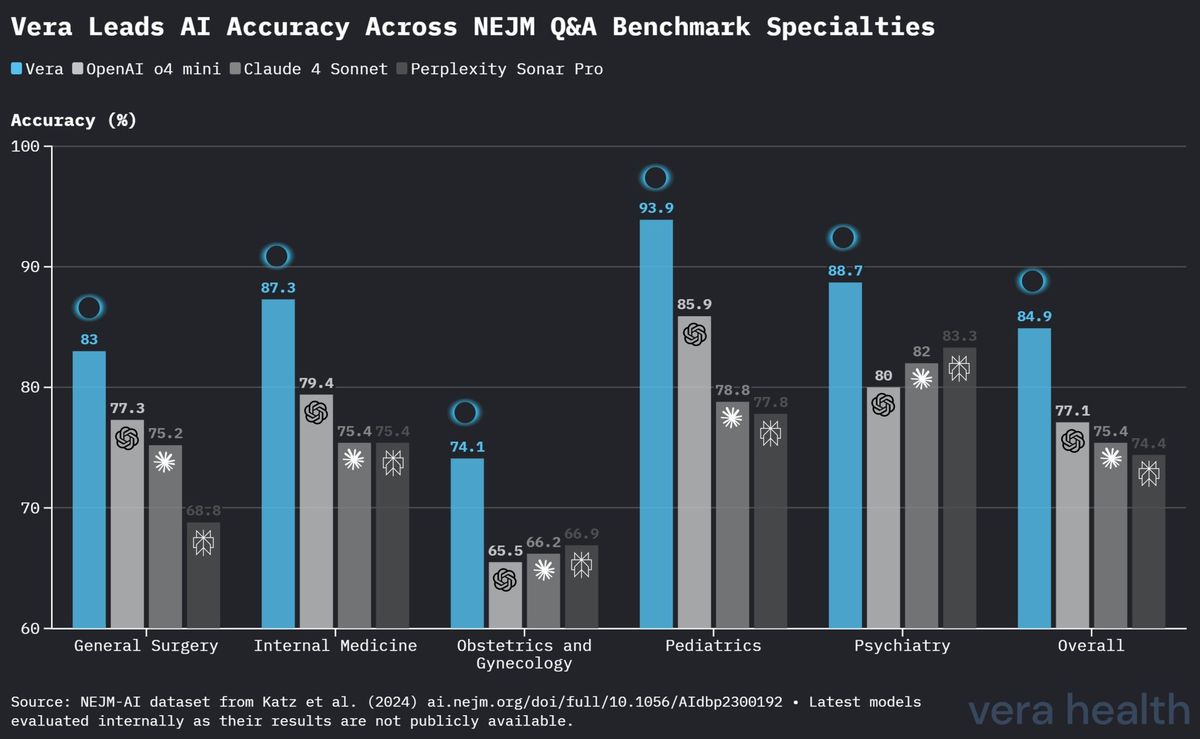
Vera 在五个专科中的四个取得了最高准确率: - 儿科:以 93.9 % 的准确率领先 - 内科:以 87.3 % 的准确率表现出色 - 普通外科:以 83.0 % 的准确率取得竞争优势 - 妇产科:以 74.1 % 的准确率略微领先 - 精神科:以 88.7 % 的准确率表现出色
MedXpertQA 性能分析
在 MedXpertQA 基准测试中,Vera 在 500 道多样化医学题目上取得了 62.2 % 的准确率,在专科临床推理场景中表现出色。表 3 列出了不同类别的详细性能细分。
| 类别 | 题目数 | Vera 准确率 |
|---|---|---|
| 按身体系统 | ||
| 皮肤系统 | 16 | 81.2 % |
| 骨骼系统 | 81 | 72.8 % |
| 肌肉系统 | 36 | 72.2 % |
| 生殖系统 | 31 | 71.0 % |
| 消化系统 | 60 | 63.3 % |
| 内分泌系统 | 37 | 62.2 % |
| 淋巴系统 | 22 | 59.1 % |
| 神经系统 | 72 | 56.9 % |
| 呼吸系统 | 32 | 56.2 % |
| 泌尿系统 | 18 | 55.6 % |
| 心血管系统 | 68 | 51.5 % |
| 其他/无 | 27 | 48.1 % |
| 按医学任务 | ||
| 基础科学 | 139 | 66.9 % |
| 治疗 | 157 | 61.8 % |
| 诊断 | 204 | 59.3 % |
| 按题型 | ||
| 理解 | 115 | 66.1 % |
| 推理 | 385 | 61.0 % |
MedXpertQA 结果揭示了 Vera 性能中的几项值得注意的模式: - 身体系统差异:性能从 81.2 %(皮肤系统)到 48.1 %(其他/无)不等,在解剖学上界限清晰的系统中表现最强 - 医学任务性能:基础科学题目(66.9 %)的表现优于临床应用类题目,表明在基础知识方面表现更强 - 题型分析:理解类题目(66.1 %)的表现优于推理类题目(61.0 %),表明其具备有效的知识检索能力
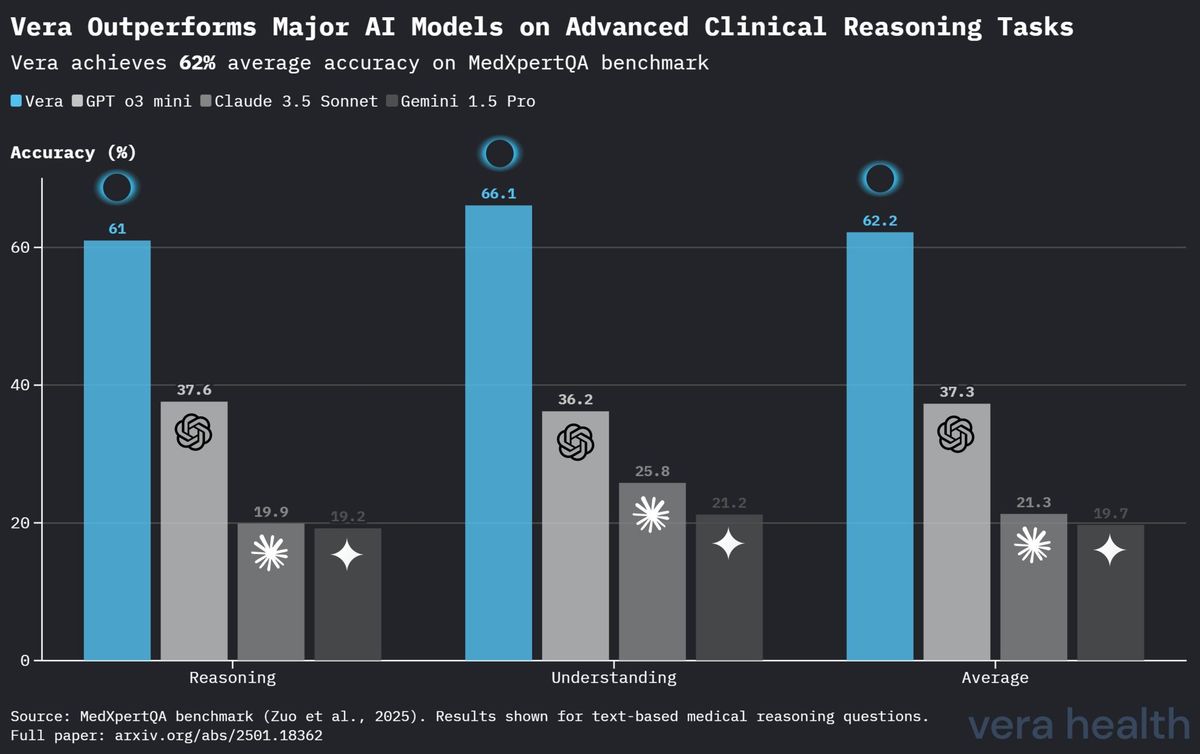
MedXpertQA 上的模型性能对比
表 4 列出了 Vera 与其他领先 AI 模型在 MedXpertQA 基准测试上的对比分析,凸显了 Vera 在专科临床推理任务中的竞争地位。
| 模型 | 推理 | 理解 | 平均 |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
方法
评估框架
我们采用三个不同的医学知识评估框架进行了综合性多基准测试评估:美国医师执照考试(USMLE)、《新英格兰医学杂志》AI 问答数据集(NEJM-AI)以及 MedXpertQA 基准测试。这种三基准测试方法能够评估基础医学知识、当代临床推理能力以及专科临床领域专长。
USMLE 评估
我们从官方 USMLE 备考资源中抽取了涵盖全部三个考试阶段的多项选择题:Step 1(基础科学)、Step 2 Clinical Knowledge(临床知识与技能)以及 Step 3(患者管理)。每道题目包含一段临床病例描述、多个答案选项、参考答案以及专科分类。题目按原文原样呈现给 Vera,使用生产环境系统提示词,未针对基准测试进行专门优化。
NEJM-AI 基准测试评估
NEJM-AI 数据集(Katz 等,2024)包含 655 道临床导向的多项选择题,分布于五大医学专科:普通外科(141 道题)、内科(126 道题)、妇产科(139 道题)、儿科(99 道题)和精神科(150 道题)。该基准测试旨在评估与执业医师相关的当代临床知识和推理能力。原始研究报告称 GPT-4 在该基准测试上取得了 74.7% 的准确率。
MedXpertQA 基准测试评估
MedXpertQA 数据集(Zuo 等,2025)是一个极具挑战性的基准测试,旨在评估专家级医学推理与理解能力。该数据集包含跨 17 个医学专科和 11 个身体系统的 4,460 道题目,是目前最全面、最困难的医学推理评估之一。该基准测试包括两个子集:用于基于文本的医学评估的 MedXpertQA Text,以及用于多模态医学评估的 MedXpertQA MM。
在本次评估中,我们使用了来自 MedXpertQA Text 子集的 500 道题目作为代表性样本,在保持该基准测试严格标准的同时实现高效评估。题目按身体系统(12 个类别)、医学任务(基础科学、诊断、治疗)和题型(理解、推理)进行分类。该基准测试评估跨广泛医学场景的专科临床知识和推理能力,从基础科学到复杂临床应用,使其在评估先进医学 AI 系统方面尤为有价值。
实验方案
对于全部三个基准测试,我们保持了一致的评估方案: - 所有题目均使用标准生产环境系统提示词呈现给 Vera,未进行任何针对基准测试的提示词工程 - 禁用了可选的 Deep Dive 模式,以模拟临床医生在真实场景中偏好的快速响应模式 - 每道题目均独立处理,无先验上下文或题目特定优化 - 响应准确率通过与所提供参考答案的精确匹配来判定
竞争分析
对于 NEJM-AI 基准测试,我们将 Vera 的性能与三个领先的医学 AI 系统进行了比较:OpenAI o4 Mini、Claude 4 Sonnet 和 Perplexity Sonar Pro。由于 OpenAI、Anthropic 和 Perplexity 的最新模型未公开提供,我们使用自有实现进行了内部评估。所有模型均在相同的 655 道题目集上使用各自的最优配置进行评估。尽管原始 NEJM-AI 研究报告称 GPT-4 取得了 74.7% 的准确率,但由于 OpenAI o4 Mini 表现更佳,我们将其排除在对比分析之外。
统计分析
我们计算了整体准确率、专科特定性能指标以及对比排名。我们分析了各专科之间的性能差异,以识别特定领域的优势和有待改进之处。
讨论
基准测试互补性及临床意义
三基准测试评估揭示了关于 Vera 能力的不同但互补的见解。卓越的 USMLE 性能(97.5 % 准确率)表明其精通涵盖基础科学、临床知识和患者管理领域的基础医学知识。强劲的 NEJM-AI 性能(84.9 % 准确率)及其相对于领先 AI 模型的竞争优势,表明其在当代临床推理场景中具备稳健的能力。MedXpertQA 性能(62.2 % 准确率)则揭示了其在专科临床领域专长以及跨多样身体系统和医学任务的推理能力。
各基准测试之间的性能差异(97.5 % 对 84.9 % 对 62.2 %)很可能反映了这些评估在性质和复杂性上的不同。USMLE 题目主要评估具有既定答案的标准化医学知识,而 NEJM-AI 题目则呈现更为微妙的临床场景,可能允许多种合理的处理方式。MedXpertQA 是其中最具挑战性的评估,包含需要整合跨多个领域专科知识的复杂临床推理场景,使其成为对高级临床能力的严格检验。
竞争定位
Vera 在 NEJM-AI 基准测试上的性能确立了相对于当前医学 AI 系统的明显竞争优势。相对于竞争模型的显著领先代表了在这一竞争激烈领域中的重大进步。更重要的是,Vera 在五个医学专科中的四个上持续保持优势,表明其具备广泛的临床知识,而非针对特定领域的优化。
专科特定结果揭示了若干重要见解: - 儿科:93.9 % 的卓越准确率表明其在一个需要专门的发育和年龄特定考量的领域中表现出色 - 内科:87.3 % 的准确率展现了其在这一基础专科所需的广泛推理方面的能力 - 妇产科:74.1 % 的相对较低准确率虽仍领先于竞争模型,但表明存在有针对性改进的潜在领域
系统泛化能力与稳健性
在多样评估框架中持续保持的高性能表明,Vera 的知识表征和推理机制能够有效泛化到不同的题型格式、难度层级和临床语境中。这种稳健性对于临床部署尤为重要,因为系统必须处理多样的查询类型和临床场景。
局限性与考量
尽管这些结果令人鼓舞,但仍有若干局限性值得考量:1. 基准测试范围:两项评估均依赖于多项选择题格式,可能无法充分体现真实临床决策的复杂性,后者往往涉及不确定性、信息不完整以及多方面的患者表现。2. 临床知识与学术知识:在学术基准测试上的高性能并不保证最佳的真实临床效果。Vera 的设计优先考虑当代临床指南和循证实践,这有时可能与历史考试答案不一致。3. 专科差异:观察到的各医学专科之间的性能差异表明,某些领域可能受益于有针对性的强化,尤其是妇产科,其性能虽具竞争力,但显示出最大的改进空间。4. 时间性考量:随着新的研究发现和指南更新,医学知识发展迅速。持续评估和模型更新对于长期保持性能至关重要。5. 评估方法学:两项基准测试均依赖于预先设定的答案,这些答案可能并不总能反映临床上可接受的全部反应范围,从而可能在模糊场景中低估系统性能。
结论
本次综合性多基准测试评估展示了 Vera 在多样医学知识领域中的卓越能力。该系统在 USMLE 上取得了近乎完美的准确率(97.5 %),在 NEJM-AI 基准测试上确立了竞争优势(84.9 %),并在极具挑战性的 MedXpertQA 基准测试上表现出色(62.2 %)。在 NEJM-AI 上,Vera 超越了包括 OpenAI o4 Mini、Claude 4 Sonnet 和 Perplexity Sonar Pro 在内的领先 AI 模型。
主要发现包括: - 广泛的医学能力:在基础(USMLE)、当代临床(NEJM-AI)和专科推理(MedXpertQA)知识领域均持续保持高性能 - 竞争优势:在正面对比评估中明显优于当前医学 AI 系统 - 专科稳健性:在 NEJM-AI 五个医学专科中的四个上表现领先,在儿科和内科方面成果尤为突出 - 特定领域专长:在 MedXpertQA 中跨多样身体系统表现强劲,在解剖学上界限清晰的系统中尤为突出(皮肤系统:81.2 %,骨骼系统:72.8 %) - 知识泛化能力:在多样题型格式、难度层级和临床语境中均表现有效
这些结果使 Vera 成为临床决策支持的领先解决方案,其展示的能力超越了当前医学 AI 系统的基准。三基准测试方法为系统在学术、临床相关和专科推理场景中的性能提供了有力证据,支持其在医学教育、临床培训和诊疗现场决策支持应用中的部署。
数据可用性
评估数据集和详细结果可应要求提供(enterprise@vera-health.ai),并将根据标准数据使用协议和隐私保障措施予以提供。
参考文献
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
关于 Vera Health
Vera 是一款由 AI 驱动的临床决策支持(CDS)工具,旨在帮助医疗服务提供者更高效地做出循证决策。Vera 利用先进的 AI 智能体和检索增强生成(RAG)技术,综合分析超过 6000 万篇经同行评审的医学文献中的知识,在诊疗现场提供可靠且符合语境的答案。凭借其前沿的 AI 技术,Vera 助力临床医生改善患者预后并简化决策流程。


