
Veraの包括的な性能評価:医学知識領域横断的なマルチベンチマーク評価
要旨
我々は、医療提供者に即時かつエビデンスに基づく医学的指針を提供することを目的とした先進的な臨床意思決定支援システムであるVeraの包括的な評価を提示する。Veraは、高度なAIエージェントと検索拡張生成(RAG)技術を活用し、6,000万件を超える査読済み医学論文から知識を統合することで、信頼性が高く文脈に適した回答を提供する。本マルチベンチマーク評価では、米国医師免許試験(USMLE)、New England Journal of MedicineのAI質問応答データセット(NEJM-AI)、およびMedXpertQAベンチマークという3つの異なる医学知識領域にわたってVeraの性能を評価する。USMLEにおいて、Veraは97.5 %という卓越した全体精度を達成し、ステップ別精度は97.9 %(Step 1)、98.2 %(Step 2 CK)、96.7 %(Step 3)であった。5つの医療専門領域にわたる655問から成るNEJM-AIベンチマークにおいて、Veraは84.9 %の精度で優れた性能を示し、OpenAI o4 Mini(77.1 %)、Claude 4 Sonnet(75.4 %)、Perplexity Sonar Pro(74.4 %)を含む主要なAIモデルを上回った。複数の身体系および医療タスクにわたる500問から成るMedXpertQAベンチマークにおいて、Veraは62.2 %の精度を達成し、専門的な臨床推論シナリオにおける高い性能を示した。Veraは5つのNEJM-AI医療専門領域のうち4つで最高精度を達成し、特に小児科(93.9 %)および内科(87.3 %)において顕著な性能を示した。多様な評価フレームワークにわたるこれらの結果は、Veraの堅牢な医学知識表現および推論能力を裏付けており、臨床意思決定支援のための主導的なソリューションとして位置づけられる。
序論
多様な臨床環境における医療提供者は、最適な患者ケアを支援するために、正確でエビデンスに基づく医学知識への迅速なアクセスを必要とする。医学文献の指数関数的な増加は、適時の知識検索および統合に前例のない課題をもたらしている。Veraは、高度なAIエージェントと先進的な検索拡張生成(RAG)技術を組み合わせることでこの重要なニーズに対応し、従来の手法と比較して約10倍の速さで信頼性の高い臨床的指針を提供する。
医療AIシステムの評価には、実世界の臨床シナリオにおける堅牢な性能を確保するために、複数の領域にわたる厳密な評価が必要である。個々のベンチマークは貴重な知見を提供するものの、多様な知識フレームワークにわたる包括的な評価は、システムの能力と限界についてより完全な全体像を提供する。本研究では、3つの相補的な評価フレームワーク、すなわち米国医師免許試験(USMLE)、New England Journal of MedicineのAI質問応答データセット(NEJM-AI)、およびMedXpertQAベンチマークを用いたVeraのマルチベンチマーク評価を提示する。
USMLEは、基礎科学、臨床知識、および患者管理の領域にわたる基礎的な医学知識の標準化された尺度を提供する。しかしながら、これは主に免許取得前の教育内容を反映するものであり、現代の臨床意思決定の複雑さを完全には捉えきれない可能性がある。この限界に対処するため、我々は5つの主要な医療専門領域にわたる655問の臨床志向の問題を提示するNEJM-AIベンチマークによって評価を補完し、より実践に関連したシナリオにおける性能に関する知見を提供する。さらに、我々は多様な身体系、医療タスク、および問題タイプにわたる臨床推論を評価する500問から成るMedXpertQAベンチマークでVeraを評価し、専門的な臨床知識領域に関するさらなる知見を提供する。
これらの異なる評価フレームワークにわたる我々の包括的な分析は、Veraの強みおよび性能特性を明らかにし、臨床意思決定支援の変革、医療提供者の効率の向上、そして最終的には患者ケアの質の改善に向けた大きな可能性を示している。
結果
マルチベンチマーク性能の概要
Veraは3つすべての評価フレームワークにわたって卓越した性能を示し、USMLEで97.5%、NEJM-AIベンチマークで84.9%、MedXpertQAベンチマークで62.2%を達成した。表1はすべての評価にわたるVeraの性能をまとめたものである。
| ベンチマーク | 精度 |
|---|---|
| USMLE(全体) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI(全体) | 84.9 % |
| MedXpertQA(全体) | 62.2 % |
USMLE性能分析
USMLE評価において、Veraはすべての試験レベルにわたってほぼ完璧な精度を達成し、堅牢な基礎的医学知識を示した。ステップ間のわずかな変動(範囲:96.7〜98.2 %)は、Veraの知識表現が基礎科学の概念から患者管理の意思決定を要する複雑な臨床シナリオまで効果的にスケールすることを示している。
USMLE競合分析
Veraの性能は、標準化された医学知識評価において他の医療AIシステムに対する明確な優位性を確立している。図1は、医療AI全体におけるVeraの競争優位性を示している。
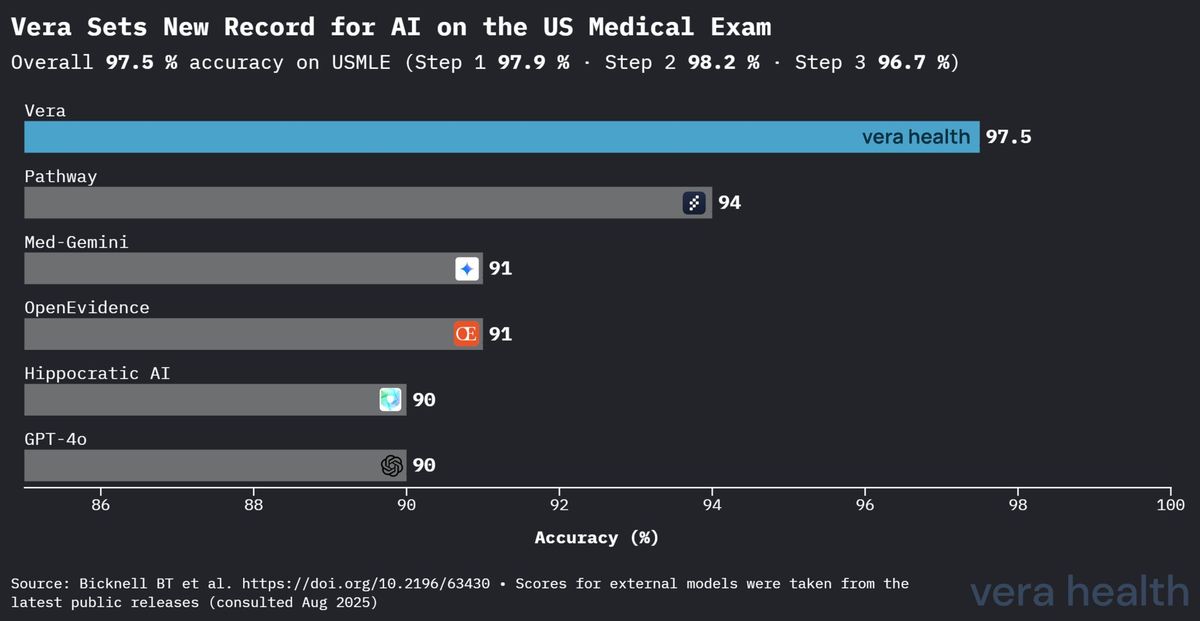
この競合分析は、いくつかの重要な知見を明らかにしている。すなわち、(1) Veraの2番目に優れたモデルに対する3.5パーセントポイントのリードは、医学知識評価における実質的な改善を表していること、(2) 汎用モデルと比較して性能差が著しく拡大し、医療特化型最適化の価値を強調していること、そして(3) Veraの優位性が専門的な医療AIシステムと主要な汎用言語モデルの双方にわたっていることである。
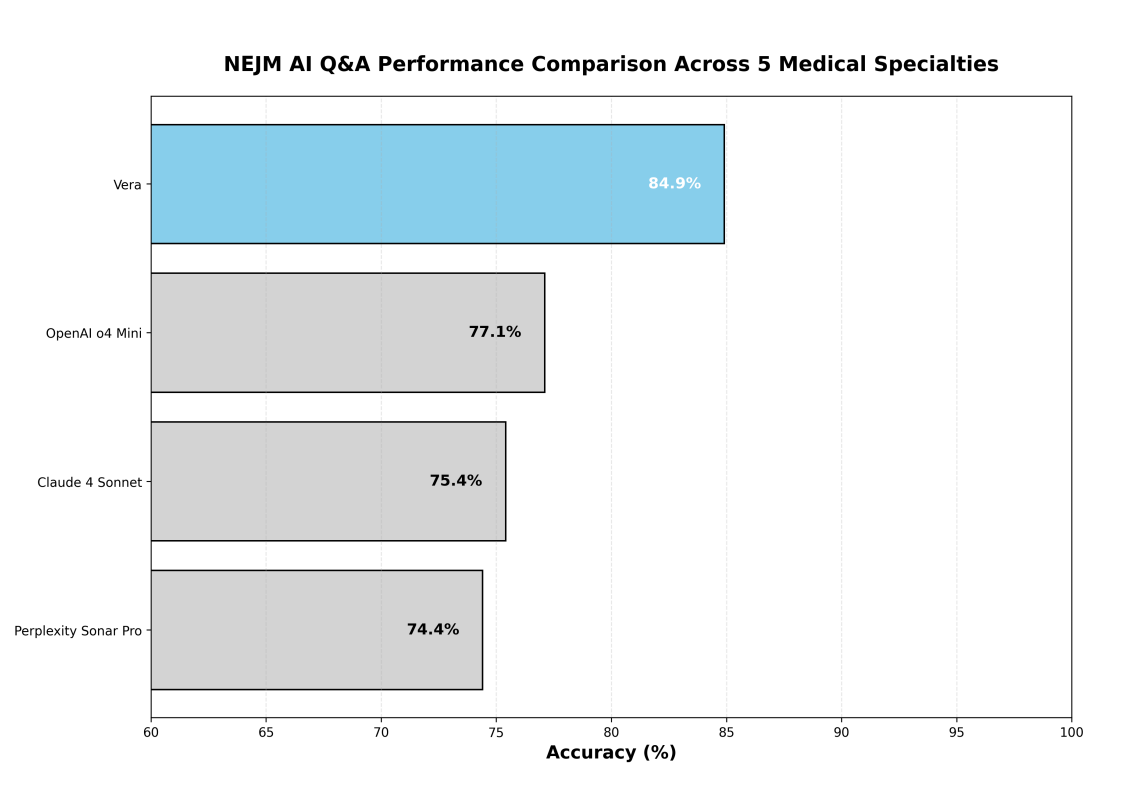
NEJM-AI競合ベンチマーク結果
NEJM-AIベンチマークにおいて、Veraは評価したすべてのモデルの中で最高の全体精度を達成し、主要なAIシステムを大きな差で上回った。図2はVeraの競争上の優位性を示している。
専門領域別性能分析
Veraの性能は医療専門領域によって異なり、ほとんどの領域で一貫して高い結果を示した。表2は専門領域別の詳細な精度を示している。
| 医療専門領域 | 問題数 | Vera精度 |
|---|---|---|
| 小児科 | 99 | 93.9 % |
| 精神科 | 150 | 88.7 % |
| 内科 | 126 | 87.3 % |
| 一般外科 | 141 | 83.0 % |
| 産婦人科 | 139 | 74.1 % |
図3は、5つすべての医療専門領域にわたるVeraと競合モデルの性能の詳細な比較を提供している。
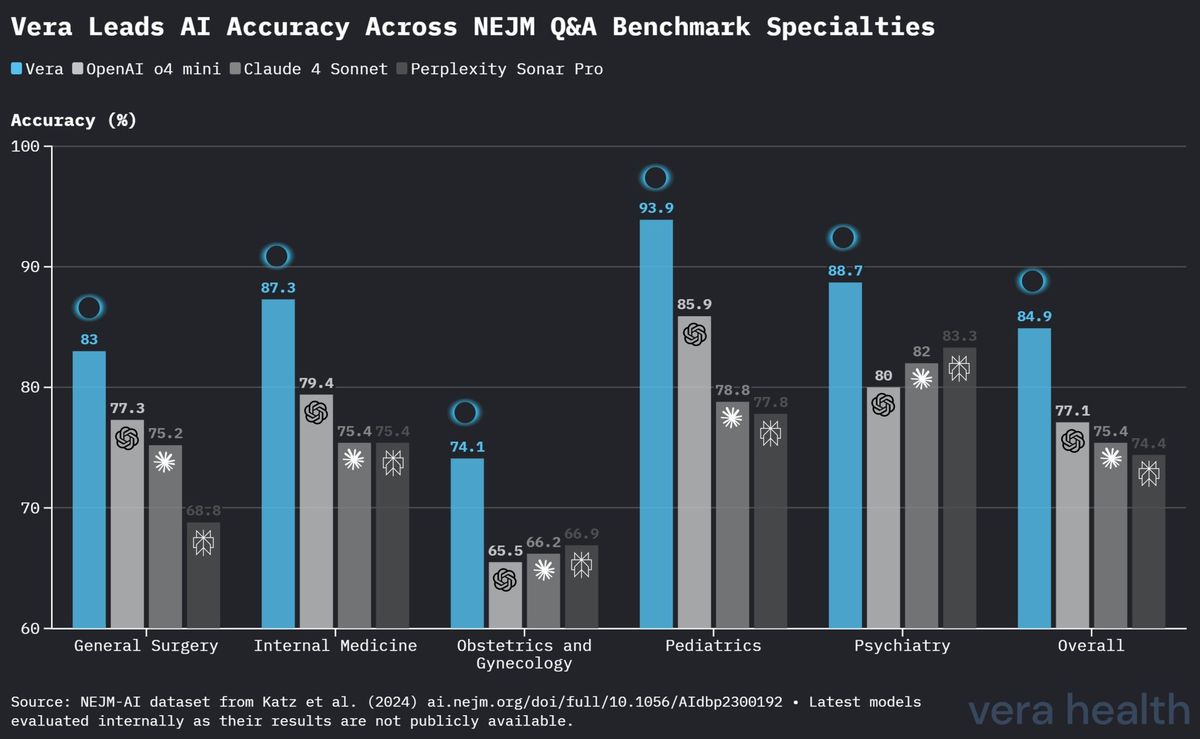
Veraは5つの専門領域のうち4つで最高精度を達成した: - 小児科:93.9 %の精度で主導的な性能 - 内科:87.3 %の精度で高い性能 - 一般外科:83.0 %の精度で競争上の優位性 - 産婦人科:74.1 %の精度でわずかなリード - 精神科:88.7 %の精度で高い性能
MedXpertQA性能分析
MedXpertQAベンチマークにおいて、Veraは500問の多様な医学的問題にわたって62.2 %の精度を達成し、専門的な臨床推論シナリオにおける確かな性能を示した。表3はさまざまなカテゴリにわたる詳細な性能の内訳を示している。
| カテゴリ | 問題数 | Vera精度 |
|---|---|---|
| 身体系別 | ||
| 外皮系 | 16 | 81.2 % |
| 骨格系 | 81 | 72.8 % |
| 筋系 | 36 | 72.2 % |
| 生殖系 | 31 | 71.0 % |
| 消化器系 | 60 | 63.3 % |
| 内分泌系 | 37 | 62.2 % |
| リンパ系 | 22 | 59.1 % |
| 神経系 | 72 | 56.9 % |
| 呼吸器系 | 32 | 56.2 % |
| 泌尿器系 | 18 | 55.6 % |
| 循環器系 | 68 | 51.5 % |
| その他/該当なし | 27 | 48.1 % |
| 医療タスク別 | ||
| 基礎科学 | 139 | 66.9 % |
| 治療 | 157 | 61.8 % |
| 診断 | 204 | 59.3 % |
| 問題タイプ別 | ||
| 理解 | 115 | 66.1 % |
| 推論 | 385 | 61.0 % |
MedXpertQAの結果は、Veraの性能におけるいくつかの注目すべきパターンを明らかにしている: - 身体系による変動:性能は81.2 %(外皮系)から48.1 %(その他/該当なし)まで幅があり、解剖学的に明確な系で最も高い性能を示した - 医療タスク性能:基礎科学の問題(66.9 %)は臨床応用を上回り、基礎的知識におけるより高い性能を示唆している - 問題タイプ分析:理解の問題(66.1 %)は推論の問題(61.0 %)と比較して優れた性能を示し、効果的な知識検索能力を示している
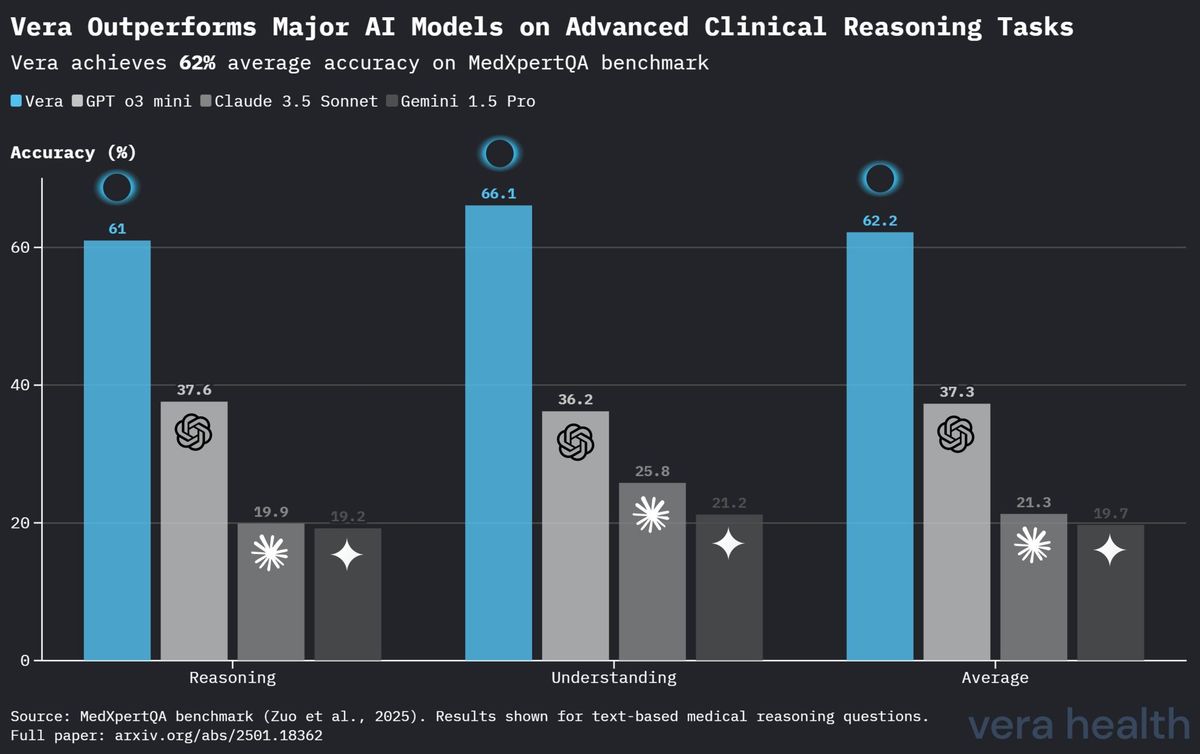
MedXpertQAにおけるモデル性能の比較
表4は、MedXpertQAベンチマークにおけるVeraと他の主要なAIモデルの性能の比較分析を提示し、専門的な臨床推論タスクにおけるVeraの競争上の位置づけを強調している。
| モデル | 推論 | 理解 | 平均 |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
方法
評価フレームワーク
我々は、3つの異なる医学知識評価フレームワーク、すなわち米国医師免許試験(USMLE)、New England Journal of MedicineのAI質問応答データセット(NEJM-AI)、およびMedXpertQAベンチマークを用いた包括的なマルチベンチマーク評価を実施した。この3ベンチマークアプローチにより、基礎的な医学知識、現代の臨床推論能力、および専門的な臨床領域の専門性を評価することが可能となる。
USMLE評価
我々は、3つすべての試験ステップ、すなわちStep 1(基礎科学)、Step 2 Clinical Knowledge(臨床知識および技能)、Step 3(患者管理)にわたる公式のUSMLE準備資料から多肢選択問題をサンプリングした。各問題は、臨床症例、複数の選択肢、参照解答キー、および専門領域分類から構成されていた。問題は、ベンチマーク特化型の最適化を行わず、本番システムプロンプトを用いて、記載されたとおりに正確にVeraに提示された。
NEJM-AIベンチマーク評価
NEJM-AIデータセット(Katz et al., 2024)は、5つの主要な医療専門領域、すなわち一般外科(141問)、内科(126問)、産婦人科(139問)、小児科(99問)、精神科(150問)に分布する655問の臨床志向の多肢選択問題から構成される。このベンチマークは、現役の医師に関連する現代の臨床知識および推論能力を評価するために設計された。元の研究では、GPT-4がこのベンチマークで74.7%の精度を達成したと報告されている。
MedXpertQAベンチマーク評価
MedXpertQAデータセット(Zuo et al., 2025)は、専門家レベルの医学的推論および理解を評価するために設計された、極めて挑戦的なベンチマークである。17の医療専門領域および11の身体系にわたる4,460問から構成され、MedXpertQAは利用可能な最も包括的かつ難易度の高い医学的推論評価の一つを代表している。本ベンチマークには2つのサブセットが含まれる。すなわち、テキストベースの医学的評価のためのMedXpertQA Textと、マルチモーダルの医学的評価のためのMedXpertQA MMである。
我々の評価では、MedXpertQA Textサブセットから代表的な500問のサンプルを利用し、ベンチマークの厳密な基準を維持しつつ効率的な評価を可能にした。問題は身体系(12カテゴリ)、医療タスク(基礎科学、診断、治療)、および問題タイプ(理解、推論)によって分類されている。このベンチマークは、基礎科学から複雑な臨床応用に至るまで、広範な医学的シナリオにわたる専門的な臨床知識および推論能力を評価するものであり、先進的な医療AIシステムの評価において特に有用である。
実験プロトコル
3つすべてのベンチマークについて、我々は一貫した評価プロトコルを維持した: - すべての問題は、ベンチマーク特化型のプロンプトエンジニアリングを行わずに、標準的な本番システムプロンプトを用いてVeraに提示された - オプションのDeep Diveモードは、実世界の環境で臨床医が好む高速応答モードを反映するため無効化された - 各問題は、事前の文脈や問題特化型の最適化なしに独立して処理された - 応答の精度は、提供された参照解答との完全一致によって判定された
競合分析
NEJM-AIベンチマークについて、我々はVeraの性能を3つの主要な医療AIシステム、すなわちOpenAI o4 Mini、Claude 4 Sonnet、およびPerplexity Sonar Proと比較した。OpenAI、Anthropic、およびPerplexityの最新モデルは一般には利用できないため、我々は独自の実装を用いて内部評価を実施した。すべてのモデルは、それぞれの最適な構成を用いて同一の655問のセットで評価された。元のNEJM-AI研究ではGPT-4が74.7%の精度を達成したと報告されているが、OpenAI o4 Miniがより優れた性能を示したため、我々はGPT-4を比較分析から除外した。
統計分析
我々は、全体精度率、専門領域別の性能指標、および比較ランキングを算出した。専門領域間の性能変動を分析し、領域特有の強みおよび改善すべき点を特定した。
考察
ベンチマークの相補性および臨床的意義
3ベンチマーク評価は、Veraの能力に関する明確でありながら相補的な知見を明らかにしている。卓越したUSMLE性能(97.5 %の精度)は、基礎科学、臨床知識、および患者管理の領域にわたる基礎的な医学知識の習熟を示している。主要なAIモデルに対する競争上の優位性を伴う高いNEJM-AI性能(84.9 %の精度)は、現代の臨床推論シナリオにおける堅牢な能力を示している。MedXpertQA性能(62.2 %の精度)は、多様な身体系および医療タスクにわたる専門的な臨床領域の専門性および推論に関する知見を提供している。
ベンチマーク間の性能差(97.5 % 対 84.9 % 対 62.2 %)は、これらの評価の異なる性質および複雑さを反映している可能性が高い。USMLEの問題は主に確立された解答キーを伴う標準化された医学知識を評価するのに対し、NEJM-AIの問題は複数の妥当なアプローチを許容しうるより微妙な臨床シナリオを提示する。MedXpertQAは最も挑戦的な評価を代表し、複数の領域にわたる専門知識の統合を要する複雑な臨床推論シナリオを特徴とし、先進的な臨床能力の厳密な試験となっている。
競争上の位置づけ
NEJM-AIベンチマークにおけるVeraの性能は、現在の医療AIシステムに対する明確な競争優位性を確立している。競合モデルに対する実質的なリードは、競争の激しい分野における重要な改善を表している。さらに重要なことに、5つの医療専門領域のうち4つにわたるVeraの一貫した優位性は、領域特化型の最適化ではなく広範な臨床知識を示している。
専門領域別の結果は、重要な知見を明らかにしている: - 小児科:93.9 %という卓越した精度は、専門的な発達上および年齢特有の考慮を要する領域における高い性能を示唆している - 内科:87.3 %の精度は、この基礎的な専門領域に必要とされる広範な推論における能力を示している - 産婦人科:比較的低い74.1 %の精度は、依然として競合をリードしているものの、的を絞った改善が可能な領域を示している
システムの汎化性および堅牢性
多様な評価フレームワークにわたる一貫して高い性能は、Veraの知識表現および推論メカニズムが、異なる問題形式、難易度、および臨床的文脈にわたって効果的に汎化することを示唆している。この堅牢性は、システムが多様なクエリタイプおよび臨床シナリオを扱わなければならない臨床展開において特に重要である。
限界および留意点
これらの有望な結果にもかかわらず、いくつかの限界が考慮に値する。1. ベンチマークの範囲:いずれの評価も、不確実性、不完全な情報、および多面的な患者の症状を伴うことが多い実世界の臨床意思決定の複雑さを完全には捉えきれない可能性のある多肢選択形式に依存している。2. 臨床知識と学術知識:学術的ベンチマークにおける高い性能は、実世界の臨床における最適な有効性を保証するものではない。Veraの設計は現代の臨床ガイドラインおよびエビデンスに基づく実践を優先しており、これは時に過去の試験解答キーと乖離する場合がある。3. 専門領域による変動:観察された医療専門領域間の性能変動は、特定の領域が的を絞った強化から恩恵を受けうることを示唆しており、特に産婦人科では性能が競争力を持ちつつも最大の改善の余地を示した。4. 時間的考慮:医学知識は新たな研究知見およびガイドラインの更新とともに急速に進化する。継続的な評価およびモデルの更新は、長期にわたって性能を維持するために不可欠である。5. 評価方法論:いずれのベンチマークも、臨床的に許容される応答の全範囲を常に反映するとは限らない事前に定められた解答キーに依存しており、曖昧なシナリオにおいてシステム性能を過小評価する可能性がある。
結論
この包括的なマルチベンチマーク評価は、多様な医学知識領域にわたるVeraの卓越した能力を示している。本システムは、USMLEでほぼ完璧な精度(97.5 %)を達成し、NEJM-AIベンチマークで競争上の優位性(84.9 %)を確立し、挑戦的なMedXpertQAベンチマークで確かな性能(62.2 %)を示した。NEJM-AIにおいて、VeraはOpenAI o4 Mini、Claude 4 Sonnet、およびPerplexity Sonar Proを含む主要なAIモデルを上回った。
主な知見には以下が含まれる: - 広範な医学的能力:基礎的(USMLE)、現代の臨床(NEJM-AI)、および専門的推論(MedXpertQA)の知識領域にわたる一貫して高い性能 - 競争優位性:直接対決の評価における現在の医療AIシステムに対する明確な優位性 - 専門領域の堅牢性:5つのNEJM-AI医療専門領域のうち4つで主導的な性能を示し、特に小児科および内科において顕著な結果 - 領域特有の専門性:MedXpertQAにおける多様な身体系にわたる高い性能、特に解剖学的に明確な系(外皮系:81.2 %、骨格系:72.8 %)における強み - 知識の汎化:多様な問題形式、難易度、および臨床的文脈にわたる効果的な性能
これらの結果は、医療AIシステムの現在のベンチマークを上回る実証された能力をもって、Veraを臨床意思決定支援のための主導的なソリューションとして位置づけている。3ベンチマークアプローチは、学術的、臨床関連、および専門的推論のシナリオにわたるシステム性能の堅牢な証拠を提供し、医学教育、臨床研修、およびケアの現場における意思決定支援アプリケーションへの展開を支持している。
データの利用可能性
評価データセットおよび詳細な結果は要請に応じて利用可能であり(enterprise@vera-health.ai)、標準的なデータ利用契約およびプライバシー保護措置を条件として提供される。
参考文献
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Vera Healthについて
Veraは、医療提供者がより効率的にエビデンスに基づく意思決定を行うことを支援するために設計された、AIを活用した臨床意思決定支援(CDS)ツールである。Veraは、高度なAIエージェントと検索拡張生成(RAG)技術を活用し、6,000万件を超える査読済み医学論文から知識を統合することで、ケアの現場において信頼性が高く文脈に適した回答を提供する。最先端のAI技術により、Veraは臨床医が患者アウトカムを改善し、意思決定プロセスを効率化することを可能にする。


