
Umfassende Leistungsbewertung von Vera: Eine Multi-Benchmark-Analyse über medizinische Wissensdomänen hinweg
Zusammenfassung
Wir präsentieren eine umfassende Bewertung von Vera, einem fortschrittlichen klinischen Entscheidungsunterstützungssystem, das darauf ausgelegt ist, Gesundheitsdienstleistern sofortige, evidenzbasierte medizinische Orientierung zu bieten. Vera nutzt hochentwickelte KI-Agenten und Retrieval-Augmented-Generation-Technologie und synthetisiert Wissen aus über 60 Millionen begutachteten medizinischen Publikationen, um zuverlässige, kontextgerechte Antworten zu liefern. Diese Multi-Benchmark-Analyse bewertet die Leistung von Vera über drei unterschiedliche medizinische Wissensdomänen hinweg: das United States Medical Licensing Examination (USMLE), den AI-Frage-Antwort-Datensatz des New England Journal of Medicine (NEJM-AI) und den MedXpertQA-Benchmark. Beim USMLE erreichte Vera eine außergewöhnliche Gesamtgenauigkeit von 97.5 %, mit schrittspezifischen Genauigkeiten von 97.9 % (Step 1), 98.2 % (Step 2 CK) und 96.7 % (Step 3). Beim NEJM-AI-Benchmark, der 655 Fragen aus fünf medizinischen Fachgebieten umfasst, zeigte Vera eine überlegene Leistung mit 84.9 % Genauigkeit und übertraf führende KI-Modelle, darunter OpenAI o4 Mini (77.1 %), Claude 4 Sonnet (75.4 %) und Perplexity Sonar Pro (74.4 %). Beim MedXpertQA-Benchmark, der 500 Fragen über mehrere Körpersysteme und medizinische Aufgaben hinweg umfasst, erreichte Vera 62.2 % Genauigkeit und zeigte damit eine starke Leistung in spezialisierten klinischen Argumentationsszenarien. Vera erzielte in vier von fünf medizinischen Fachgebieten des NEJM-AI die höchste Genauigkeit, mit besonders starker Leistung in der Pädiatrie (93.9 %) und der Inneren Medizin (87.3 %). Diese Ergebnisse über verschiedene Bewertungsrahmen hinweg unterstreichen Veras robuste Repräsentation medizinischen Wissens und ihre Argumentationsfähigkeiten und positionieren sie als führende Lösung für die klinische Entscheidungsunterstützung.
Einleitung
Gesundheitsdienstleister in unterschiedlichen klinischen Umgebungen benötigen schnellen Zugang zu präzisem, evidenzbasiertem medizinischem Wissen, um eine optimale Patientenversorgung zu unterstützen. Das exponentielle Wachstum der medizinischen Literatur stellt beispiellose Herausforderungen für den zeitnahen Wissensabruf und dessen Synthese dar. Vera adressiert diesen kritischen Bedarf, indem sie hochentwickelte KI-Agenten mit fortschrittlicher Retrieval-Augmented-Generation-Technologie kombiniert und zuverlässige klinische Orientierung etwa zehnmal schneller als herkömmliche Methoden liefert.
Die Bewertung medizinischer KI-Systeme erfordert eine rigorose Analyse über mehrere Domänen hinweg, um eine robuste Leistung in realen klinischen Szenarien sicherzustellen. Während einzelne Benchmarks wertvolle Erkenntnisse liefern, bietet eine umfassende Bewertung über verschiedene Wissensrahmen hinweg ein vollständigeres Bild der Systemfähigkeiten und -grenzen. Diese Studie präsentiert eine Multi-Benchmark-Bewertung von Vera anhand dreier komplementärer Bewertungsrahmen: des United States Medical Licensing Examination (USMLE), des AI-Frage-Antwort-Datensatzes des New England Journal of Medicine (NEJM-AI) und des MedXpertQA-Benchmarks.
Das USMLE bietet ein standardisiertes Maß für grundlegendes medizinisches Wissen in den Bereichen Grundlagenwissenschaft, klinisches Wissen und Patientenmanagement. Es spiegelt jedoch in erster Linie Bildungsinhalte vor der Approbation wider und erfasst möglicherweise nicht vollständig die Komplexität der zeitgenössischen klinischen Entscheidungsfindung. Um diese Einschränkung zu adressieren, ergänzen wir unsere Bewertung durch den NEJM-AI-Benchmark, der 655 klinisch orientierte Fragen aus fünf großen medizinischen Fachgebieten präsentiert und Einblicke in die Leistung bei praxisrelevanteren Szenarien bietet. Zusätzlich bewerten wir Vera anhand des MedXpertQA-Benchmarks, der 500 Fragen umfasst, die klinisches Denken über verschiedene Körpersysteme, medizinische Aufgaben und Fragetypen hinweg bewerten und weitere Einblicke in spezialisierte klinische Wissensdomänen liefern.
Unsere umfassende Analyse über diese unterschiedlichen Bewertungsrahmen hinweg offenbart Veras Stärken und Leistungsmerkmale und zeigt erhebliches Potenzial, die klinische Entscheidungsunterstützung zu transformieren, die Effizienz der Leistungserbringer zu steigern und letztlich die Qualität der Patientenversorgung zu verbessern.
Ergebnisse
Überblick über die Multi-Benchmark-Leistung
Vera zeigte eine außergewöhnliche Leistung über alle drei Bewertungsrahmen hinweg und erreichte 97.5 % beim USMLE, 84.9 % beim NEJM-AI-Benchmark und 62.2 % beim MedXpertQA-Benchmark. Tabelle 1 fasst Veras Leistung über alle Bewertungen hinweg zusammen.
| Benchmark | Genauigkeit |
|---|---|
| USMLE (Gesamt) | 97.5 % |
| Step 1 | 97.9 % |
| Step 2 CK | 98.2 % |
| Step 3 | 96.7 % |
| NEJM-AI (Gesamt) | 84.9 % |
| MedXpertQA (Gesamt) | 62.2 % |
Analyse der USMLE-Leistung
Bei der USMLE-Bewertung erreichte Vera eine nahezu perfekte Genauigkeit über alle Prüfungsstufen hinweg und demonstrierte damit ein robustes grundlegendes medizinisches Wissen. Die minimale Variation zwischen den Schritten (Bereich: 96.7–98.2 %) zeigt, dass Veras Wissensrepräsentation effektiv von grundlagenwissenschaftlichen Konzepten bis hin zu komplexen klinischen Szenarien skaliert, die Entscheidungen zum Patientenmanagement erfordern.
Wettbewerbsanalyse zum USMLE
Veras Leistung begründet eine klare Überlegenheit gegenüber anderen medizinischen KI-Systemen bei der standardisierten Bewertung medizinischen Wissens. Abbildung 1 verdeutlicht Veras Wettbewerbsvorteil in der Landschaft der medizinischen KI.
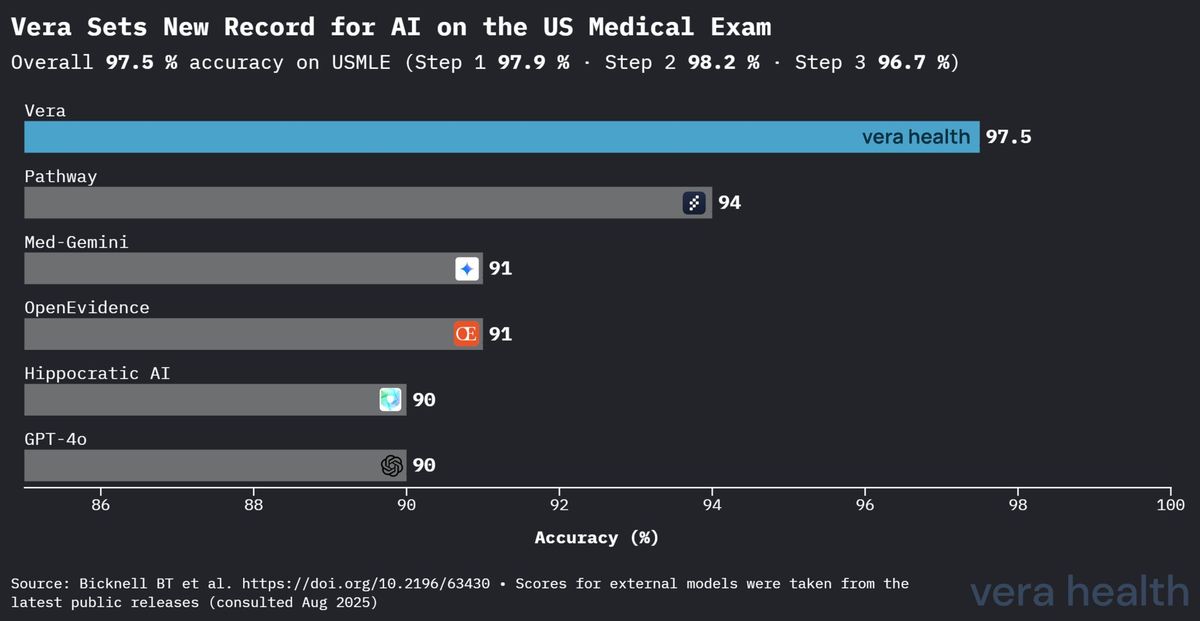
Diese Wettbewerbsanalyse offenbart mehrere zentrale Erkenntnisse: (1) Veras Vorsprung von 3,5 Prozentpunkten gegenüber dem zweitbesten Modell stellt eine erhebliche Verbesserung bei der Bewertung medizinischen Wissens dar; (2) die Leistungslücke vergrößert sich im Vergleich zu Allzweckmodellen deutlich, was den Wert der medizinspezifischen Optimierung unterstreicht; und (3) Veras Überlegenheit erstreckt sich sowohl auf spezialisierte medizinische KI-Systeme als auch auf führende Allzweck-Sprachmodelle.
Wettbewerbsbenchmark-Ergebnisse zu NEJM-AI
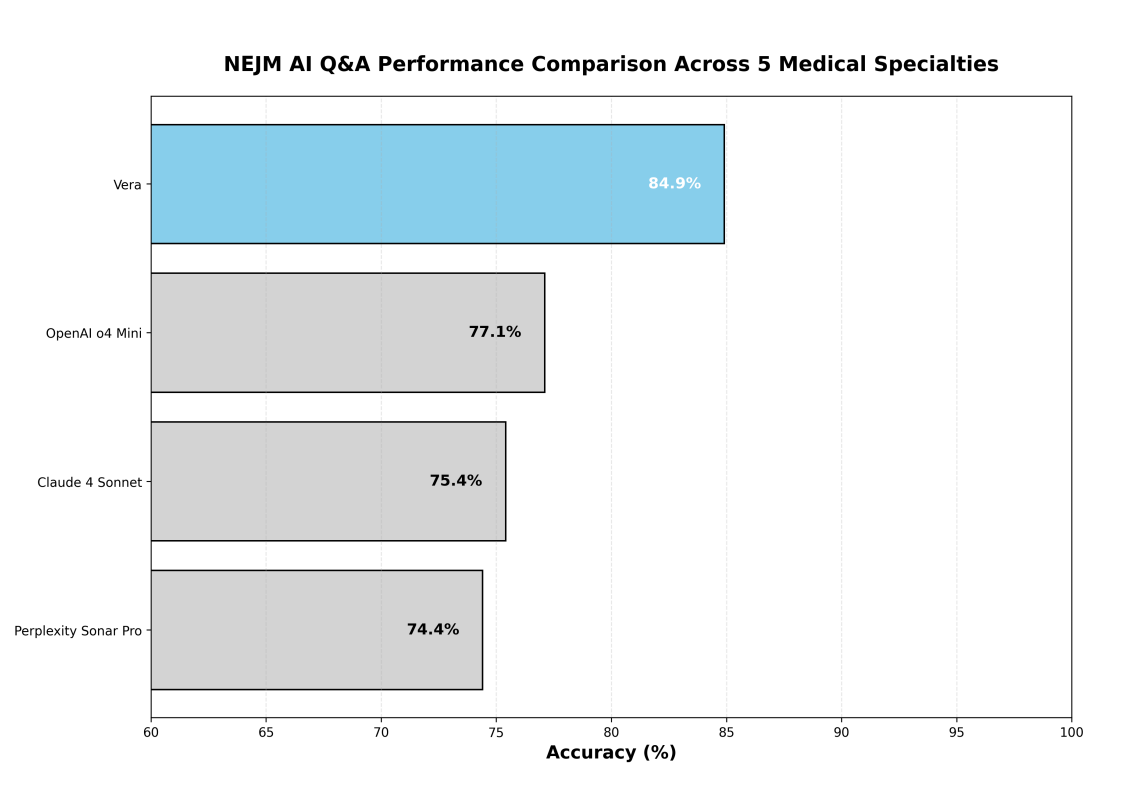
Beim NEJM-AI-Benchmark erreichte Vera die höchste Gesamtgenauigkeit unter allen bewerteten Modellen und übertraf führende KI-Systeme mit erheblichem Abstand. Abbildung 2 verdeutlicht Veras Wettbewerbsüberlegenheit.
Analyse der fachgebietsspezifischen Leistung
Veras Leistung variierte über die medizinischen Fachgebiete hinweg, mit durchgängig starken Ergebnissen in den meisten Domänen. Tabelle 2 zeigt detaillierte fachgebietsspezifische Genauigkeiten.
| Medizinisches Fachgebiet | Fragen | Vera-Genauigkeit |
|---|---|---|
| Pädiatrie | 99 | 93.9 % |
| Psychiatrie | 150 | 88.7 % |
| Innere Medizin | 126 | 87.3 % |
| Allgemeinchirurgie | 141 | 83.0 % |
| Gynäkologie und Geburtshilfe | 139 | 74.1 % |
Abbildung 3 bietet einen detaillierten Vergleich von Veras Leistung mit konkurrierenden Modellen über alle fünf medizinischen Fachgebiete hinweg.
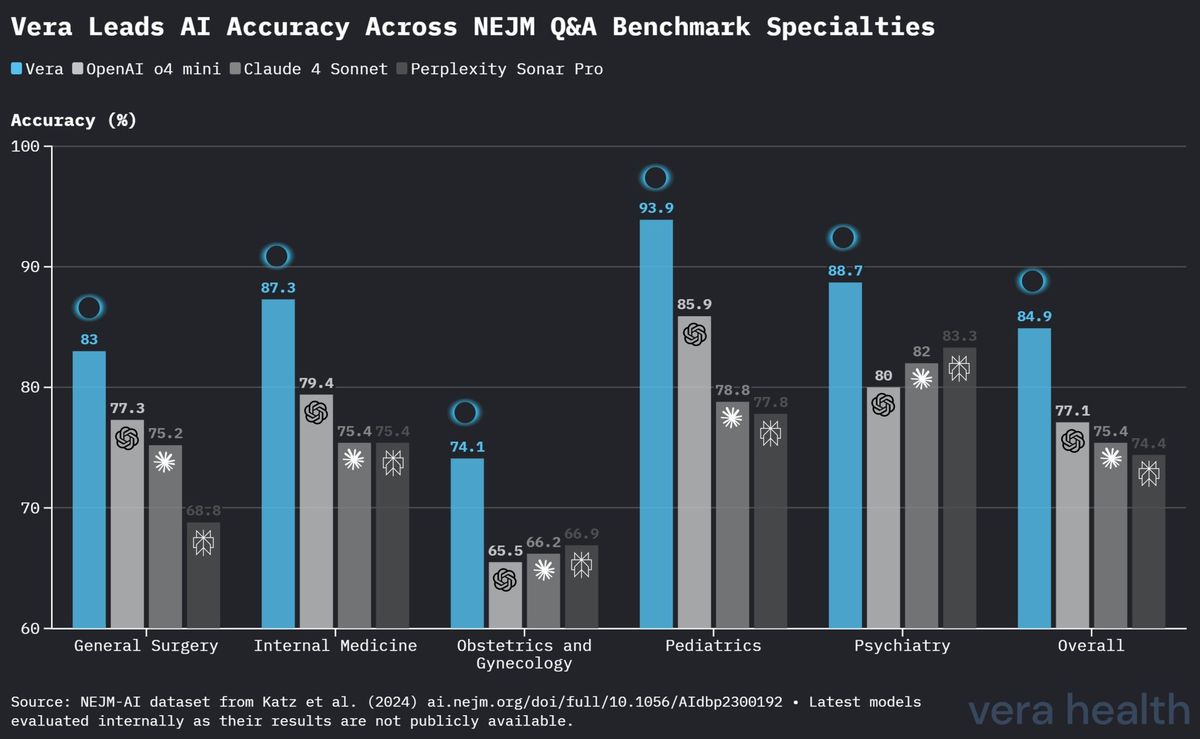
Vera erzielte in vier von fünf Fachgebieten die höchste Genauigkeit: - Pädiatrie: Führende Leistung mit 93.9 % Genauigkeit - Innere Medizin: Starke Leistung mit 87.3 % Genauigkeit - Allgemeinchirurgie: Wettbewerbsvorteil mit 83.0 % Genauigkeit - Gynäkologie und Geburtshilfe: Knapper Vorsprung mit 74.1 % Genauigkeit - Psychiatrie: Starke Leistung mit 88.7 % Genauigkeit
Analyse der MedXpertQA-Leistung
Beim MedXpertQA-Benchmark erreichte Vera 62.2 % Genauigkeit über 500 verschiedene medizinische Fragen hinweg und zeigte damit eine kompetente Leistung in spezialisierten klinischen Argumentationsszenarien. Tabelle 3 zeigt detaillierte Leistungsaufschlüsselungen über verschiedene Kategorien hinweg.
| Kategorie | Fragen | Vera-Genauigkeit |
|---|---|---|
| Nach Körpersystem | ||
| Integument (Haut) | 16 | 81.2 % |
| Skelettsystem | 81 | 72.8 % |
| Muskulatur | 36 | 72.2 % |
| Reproduktionssystem | 31 | 71.0 % |
| Verdauungssystem | 60 | 63.3 % |
| Endokrines System | 37 | 62.2 % |
| Lymphsystem | 22 | 59.1 % |
| Nervensystem | 72 | 56.9 % |
| Atmungssystem | 32 | 56.2 % |
| Harnsystem | 18 | 55.6 % |
| Herz-Kreislauf-System | 68 | 51.5 % |
| Sonstige/k.A. | 27 | 48.1 % |
| Nach medizinischer Aufgabe | ||
| Grundlagenwissenschaft | 139 | 66.9 % |
| Behandlung | 157 | 61.8 % |
| Diagnose | 204 | 59.3 % |
| Nach Fragetyp | ||
| Verständnis | 115 | 66.1 % |
| Argumentation | 385 | 61.0 % |
Die MedXpertQA-Ergebnisse offenbaren mehrere bemerkenswerte Muster in Veras Leistung: - Variation nach Körpersystem: Die Leistung reichte von 81.2 % (Integument (Haut)) bis 48.1 % (Sonstige/k.A.), mit der stärksten Leistung in anatomisch abgegrenzten Systemen - Leistung nach medizinischer Aufgabe: Fragen zur Grundlagenwissenschaft (66.9 %) übertrafen klinische Anwendungen, was auf eine stärkere Leistung bei grundlegendem Wissen hindeutet - Analyse nach Fragetyp: Verständnisfragen (66.1 %) zeigten eine überlegene Leistung im Vergleich zu Argumentationsfragen (61.0 %), was auf effektive Fähigkeiten zum Wissensabruf hinweist
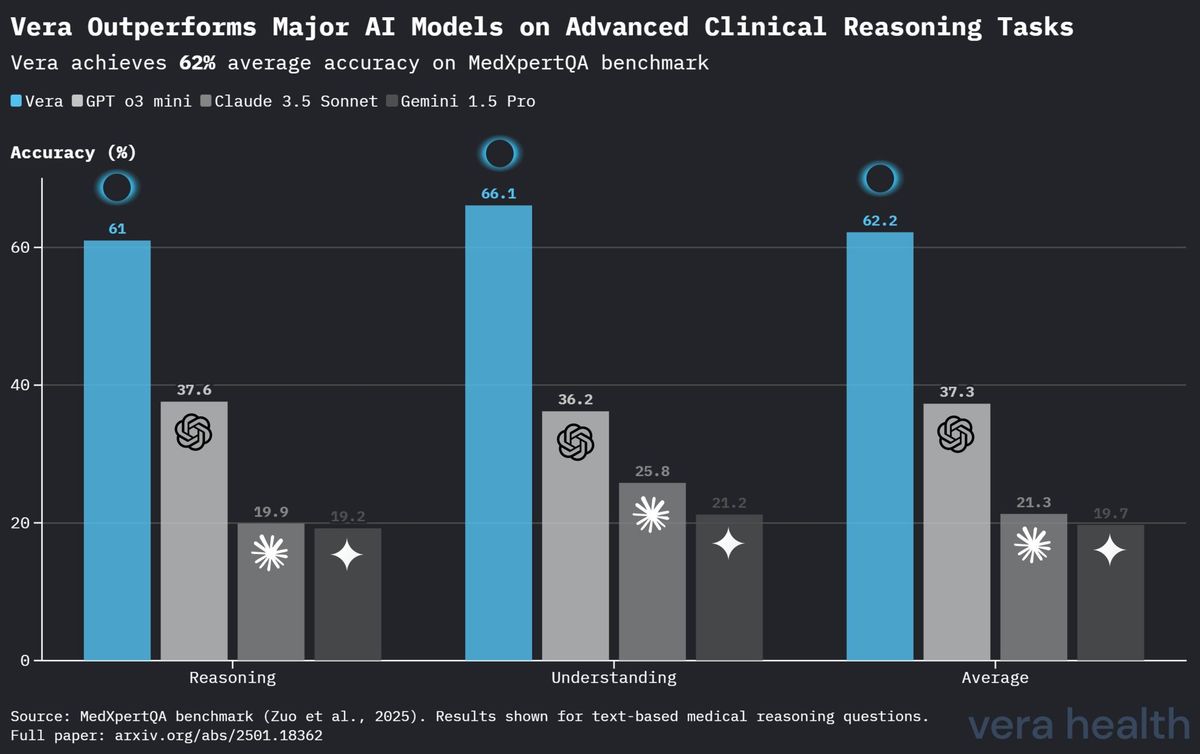
Vergleichende Modellleistung bei MedXpertQA
Tabelle 4 zeigt eine vergleichende Analyse von Veras Leistung im Vergleich zu anderen führenden KI-Modellen beim MedXpertQA-Benchmark und hebt Veras Wettbewerbsposition bei spezialisierten klinischen Argumentationsaufgaben hervor.
| Modell | Argumentation | Verständnis | Durchschnitt |
|---|---|---|---|
| Vera | 61.0 % | 66.1 % | 62.2 % |
| OpenAI o3 Mini | 37.6 % | 36.2 % | 37.3 % |
| Claude 3.5 Sonnet | 19.9 % | 25.8 % | 21.3 % |
| Gemini 1.5 Pro | 19.2 % | 21.2 % | 19.7 % |
Methoden
Bewertungsrahmen
Wir führten eine umfassende Multi-Benchmark-Bewertung anhand dreier unterschiedlicher Rahmen zur Bewertung medizinischen Wissens durch: des United States Medical Licensing Examination (USMLE), des AI-Frage-Antwort-Datensatzes des New England Journal of Medicine (NEJM-AI) und des MedXpertQA-Benchmarks. Dieser Drei-Benchmark-Ansatz ermöglicht die Bewertung von grundlegendem medizinischem Wissen, zeitgenössischen klinischen Argumentationsfähigkeiten und spezialisierter klinischer Fachkompetenz.
USMLE-Bewertung
Wir entnahmen Multiple-Choice-Fragen aus offiziellen USMLE-Vorbereitungsmaterialien, die alle drei Prüfungsschritte umfassen: Step 1 (Grundlagenwissenschaft), Step 2 Clinical Knowledge (klinisches Wissen und Fertigkeiten) und Step 3 (Patientenmanagement). Jede Frage umfasste eine klinische Fallvignette, mehrere Antwortoptionen, einen Referenzantwortschlüssel und eine Fachgebietsklassifizierung. Die Fragen wurden Vera exakt so präsentiert, wie sie verfasst waren, unter Verwendung des Produktionssystem-Prompts ohne benchmarkspezifische Optimierung.
NEJM-AI-Benchmark-Bewertung
Der NEJM-AI-Datensatz (Katz et al., 2024) besteht aus 655 klinisch orientierten Multiple-Choice-Fragen, die auf fünf große medizinische Fachgebiete verteilt sind: Allgemeinchirurgie (141 Fragen), Innere Medizin (126 Fragen), Gynäkologie und Geburtshilfe (139 Fragen), Pädiatrie (99 Fragen) und Psychiatrie (150 Fragen). Dieser Benchmark wurde entwickelt, um zeitgenössisches klinisches Wissen und Argumentationsfähigkeiten zu bewerten, die für praktizierende Ärztinnen und Ärzte relevant sind. Die ursprüngliche Studie berichtete, dass GPT-4 bei diesem Benchmark eine Genauigkeit von 74.7 % erreichte.
MedXpertQA-Benchmark-Bewertung
Der MedXpertQA-Datensatz (Zuo et al., 2025) ist ein äußerst anspruchsvoller Benchmark, der entwickelt wurde, um medizinisches Denken und Verständnis auf Expertenniveau zu bewerten. Mit 4.460 Fragen aus 17 medizinischen Fachgebieten und 11 Körpersystemen stellt MedXpertQA eine der umfassendsten und schwierigsten medizinischen Argumentationsbewertungen dar, die verfügbar sind. Der Benchmark umfasst zwei Teilmengen: MedXpertQA Text für die textbasierte medizinische Bewertung und MedXpertQA MM für die multimodale medizinische Bewertung.
Für unsere Bewertung verwendeten wir eine repräsentative Stichprobe von 500 Fragen aus der Teilmenge MedXpertQA Text, wobei wir die rigorosen Standards des Benchmarks beibehielten und gleichzeitig eine effiziente Bewertung ermöglichten. Die Fragen sind nach Körpersystem (12 Kategorien), medizinischer Aufgabe (Grundlagenwissenschaft, Diagnose, Behandlung) und Fragetyp (Verständnis, Argumentation) kategorisiert. Dieser Benchmark bewertet spezialisiertes klinisches Wissen und Argumentationsfähigkeiten über ein breites Spektrum medizinischer Szenarien hinweg, von der grundlegenden Wissenschaft bis hin zu komplexen klinischen Anwendungen, was ihn besonders wertvoll für die Bewertung fortschrittlicher medizinischer KI-Systeme macht.
Experimentelles Protokoll
Für alle drei Benchmarks hielten wir konsistente Bewertungsprotokolle ein: - Alle Fragen wurden Vera unter Verwendung des standardmäßigen Produktionssystem-Prompts ohne jegliches benchmarkspezifisches Prompt-Engineering präsentiert - Der optionale Deep-Dive-Modus wurde deaktiviert, um den Schnellantwortmodus widerzuspiegeln, den Klinikerinnen und Kliniker in realen Umgebungen bevorzugen - Jede Frage wurde unabhängig ohne vorherigen Kontext oder fragenspezifische Optimierung verarbeitet - Die Antwortgenauigkeit wurde durch exakten Abgleich mit den bereitgestellten Referenzantworten bestimmt
Wettbewerbsanalyse
Für den NEJM-AI-Benchmark verglichen wir Veras Leistung mit drei führenden medizinischen KI-Systemen: OpenAI o4 Mini, Claude 4 Sonnet und Perplexity Sonar Pro. Da die neuesten Modelle von OpenAI, Anthropic und Perplexity nicht öffentlich verfügbar sind, führten wir interne Bewertungen mit unseren eigenen Implementierungen durch. Alle Modelle wurden auf dem identischen Satz von 655 Fragen unter Verwendung ihrer jeweils optimalen Konfigurationen bewertet. Während die ursprüngliche NEJM-AI-Studie berichtete, dass GPT-4 eine Genauigkeit von 74.7 % erreichte, haben wir es aus unserer vergleichenden Analyse ausgeschlossen, da OpenAI o4 Mini eine überlegene Leistung zeigte.
Statistische Analyse
Wir berechneten die Gesamtgenauigkeitsraten, fachgebietsspezifische Leistungskennzahlen und vergleichende Rangfolgen. Leistungsvariationen über die Fachgebiete hinweg wurden analysiert, um domänenspezifische Stärken und Verbesserungsbereiche zu identifizieren.
Diskussion
Benchmark-Komplementarität und klinische Implikationen
Die Drei-Benchmark-Bewertung offenbart unterschiedliche, aber komplementäre Einblicke in Veras Fähigkeiten. Die außergewöhnliche USMLE-Leistung (97.5 % Genauigkeit) demonstriert die Beherrschung grundlegenden medizinischen Wissens in den Bereichen Grundlagenwissenschaft, klinisches Wissen und Patientenmanagement. Die starke NEJM-AI-Leistung (84.9 % Genauigkeit) mit Wettbewerbsüberlegenheit gegenüber führenden KI-Modellen weist auf robuste Fähigkeiten in zeitgenössischen klinischen Argumentationsszenarien hin. Die MedXpertQA-Leistung (62.2 % Genauigkeit) liefert Einblicke in spezialisierte klinische Fachkompetenz und Argumentation über verschiedene Körpersysteme und medizinische Aufgaben hinweg.
Der Leistungsunterschied zwischen den Benchmarks (97.5 % vs. 84.9 % vs. 62.2 %) spiegelt wahrscheinlich die unterschiedliche Natur und Komplexität dieser Bewertungen wider. USMLE-Fragen bewerten in erster Linie standardisiertes medizinisches Wissen mit etablierten Antwortschlüsseln, während NEJM-AI-Fragen nuanciertere klinische Szenarien präsentieren, die mehrere vertretbare Ansätze zulassen können. MedXpertQA stellt die anspruchsvollste Bewertung dar und umfasst komplexe klinische Argumentationsszenarien, die die Integration spezialisierten Wissens über mehrere Domänen hinweg erfordern, was es zu einem rigorosen Test fortgeschrittener klinischer Kompetenz macht.
Wettbewerbspositionierung
Veras Leistung beim NEJM-AI-Benchmark begründet klare Wettbewerbsvorteile gegenüber aktuellen medizinischen KI-Systemen. Der erhebliche Vorsprung gegenüber konkurrierenden Modellen stellt eine bedeutende Verbesserung in einem hart umkämpften Feld dar. Noch bedeutsamer ist, dass Veras durchgängige Überlegenheit in vier von fünf medizinischen Fachgebieten ein breit angelegtes klinisches Wissen statt einer domänenspezifischen Optimierung demonstriert.
Die fachgebietsspezifischen Ergebnisse offenbaren wichtige Erkenntnisse: - Pädiatrie: Die außergewöhnliche Genauigkeit von 93.9 % deutet auf eine starke Leistung in einer Domäne hin, die spezialisierte entwicklungsbezogene und altersspezifische Überlegungen erfordert - Innere Medizin: Die Genauigkeit von 87.3 % demonstriert Kompetenz in der breit angelegten Argumentation, die für dieses grundlegende Fachgebiet erforderlich ist - Gynäkologie und Geburtshilfe: Die vergleichsweise niedrigere Genauigkeit von 74.1 %, die zwar weiterhin vor den Wettbewerbern liegt, deutet auf potenzielle Bereiche für gezielte Verbesserungen hin
Systemverallgemeinerung und Robustheit
Die durchgängig hohe Leistung über verschiedene Bewertungsrahmen hinweg legt nahe, dass Veras Wissensrepräsentation und Argumentationsmechanismen effektiv über unterschiedliche Frageformate, Schwierigkeitsgrade und klinische Kontexte hinweg generalisieren. Diese Robustheit ist besonders wichtig für den klinischen Einsatz, bei dem das System verschiedene Anfragetypen und klinische Szenarien bewältigen muss.
Einschränkungen und Überlegungen
Trotz dieser ermutigenden Ergebnisse verdienen mehrere Einschränkungen Beachtung: 1. Umfang der Benchmarks: Beide Bewertungen stützen sich auf Multiple-Choice-Formate, die die Komplexität der realen klinischen Entscheidungsfindung möglicherweise nicht vollständig erfassen, die oft mit Unsicherheit, unvollständigen Informationen und vielschichtigen Patientenpräsentationen einhergeht. 2. Klinisches vs. akademisches Wissen: Eine hohe Leistung bei akademischen Benchmarks garantiert keine optimale klinische Wirksamkeit in der Praxis. Veras Design priorisiert zeitgenössische klinische Leitlinien und evidenzbasierte Praxis, die gelegentlich von historischen Prüfungsantwortschlüsseln abweichen können. 3. Variation nach Fachgebiet: Die beobachtete Leistungsvariation über die medizinischen Fachgebiete hinweg legt nahe, dass bestimmte Domänen von gezielter Verbesserung profitieren könnten, insbesondere die Gynäkologie und Geburtshilfe, bei der die Leistung zwar wettbewerbsfähig war, aber den größten Verbesserungsspielraum zeigte. 4. Zeitliche Überlegungen: Medizinisches Wissen entwickelt sich rasch mit neuen Forschungsergebnissen und Leitlinienaktualisierungen. Eine kontinuierliche Bewertung und Modellaktualisierung wird unerlässlich sein, um die Leistung im Laufe der Zeit aufrechtzuerhalten. 5. Bewertungsmethodik: Beide Benchmarks stützen sich auf vorgegebene Antwortschlüssel, die möglicherweise nicht immer das gesamte Spektrum klinisch akzeptabler Antworten widerspiegeln, wodurch die Systemleistung in mehrdeutigen Szenarien potenziell unterschätzt wird.
Schlussfolgerungen
Diese umfassende Multi-Benchmark-Bewertung demonstriert Veras außergewöhnliche Fähigkeiten über verschiedene medizinische Wissensdomänen hinweg. Das System erreichte eine nahezu perfekte Genauigkeit beim USMLE (97.5 %), begründete eine Wettbewerbsüberlegenheit beim NEJM-AI-Benchmark (84.9 %) und zeigte eine kompetente Leistung beim anspruchsvollen MedXpertQA-Benchmark (62.2 %). Beim NEJM-AI übertraf Vera führende KI-Modelle, darunter OpenAI o4 Mini, Claude 4 Sonnet und Perplexity Sonar Pro.
Zu den zentralen Erkenntnissen gehören: - Breite medizinische Kompetenz: Durchgängig hohe Leistung über grundlegende (USMLE), zeitgenössische klinische (NEJM-AI) und spezialisierte argumentative (MedXpertQA) Wissensdomänen hinweg - Wettbewerbsvorteil: Klare Überlegenheit gegenüber aktuellen medizinischen KI-Systemen im direkten Vergleich - Robustheit über Fachgebiete hinweg: Führende Leistung in vier von fünf medizinischen Fachgebieten des NEJM-AI mit besonders starken Ergebnissen in der Pädiatrie und der Inneren Medizin - Domänenspezifische Expertise: Starke Leistung über verschiedene Körpersysteme bei MedXpertQA hinweg, mit besonderer Stärke in anatomisch abgegrenzten Systemen (Integument (Haut): 81.2 %, Skelettsystem: 72.8 %) - Wissensverallgemeinerung: Effektive Leistung über verschiedene Frageformate, Schwierigkeitsgrade und klinische Kontexte hinweg
Diese Ergebnisse positionieren Vera als führende Lösung für die klinische Entscheidungsunterstützung mit nachgewiesenen Fähigkeiten, die aktuelle Benchmarks für medizinische KI-Systeme übertreffen. Der Drei-Benchmark-Ansatz liefert robuste Belege für die Systemleistung über akademische, klinisch relevante und spezialisierte argumentative Szenarien hinweg und unterstützt den Einsatz in der medizinischen Ausbildung, im klinischen Training und in Anwendungen zur Entscheidungsunterstützung am Behandlungsort.
Datenverfügbarkeit
Die Bewertungsdatensätze und detaillierten Ergebnisse sind auf Anfrage verfügbar (enterprise@vera-health.ai) und werden vorbehaltlich standardmäßiger Datennutzungsvereinbarungen und Datenschutzmaßnahmen bereitgestellt.
Vollständige Arbeit hier lesen
Literaturverzeichnis
[1] Katz, U., Cohen, E., Shachar, E., Somer, J., Fink, A., Morse, E., Shreiber, B., & Wolf, I. (2024). GPT versus Resident Physicians — A Benchmark Based on Official Board Scores. NEJM AI, 1(5), AIdbp2300192. https://doi.org/10.1056/AIdbp2300192 [2] Zuo, Y., Qu, S., Li, Y., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., & Zhou, B. (2025). MedXpertQA: Benchmarking expert-level medical reasoning and understanding. arXiv preprint arXiv:2501.18362. [3] Bicknell, B. T., Butler, D., Whalen, S., Ricks, J., Dixon, C. J., Clark, A. B., Spaedy, O., Skelton, A., Edupuganti, N., Dzubinski, L., Tate, H., Dyess, G., Lindeman, B., & Lehmann, L. S. (2024). ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education, 10, e63430. https://doi.org/10.2196/63430
Über Vera Health
Vera ist ein KI-gestütztes klinisches Entscheidungsunterstützungssystem (CDS), das Gesundheitsdienstleister dabei unterstützt, evidenzbasierte Entscheidungen effizienter zu treffen. Vera nutzt hochentwickelte KI-Agenten und Retrieval-Augmented-Generation-Technologie und synthetisiert Wissen aus über 60 Millionen begutachteten medizinischen Publikationen, um zuverlässige, kontextgerechte Antworten am Behandlungsort zu liefern. Mit ihrer hochmodernen KI-Technologie befähigt Vera Klinikerinnen und Kliniker, Behandlungsergebnisse zu verbessern und Entscheidungsprozesse zu optimieren.


